
티스토리 뷰
밑바닥부터 시작하는 딥러닝 : 파이썬으로 익히는 딥러닝 이론과 구현
실습 환경 : google colab
3장 - 신경망
책에서는 로컬 개발환경에서 실습하도록 되어있지만
google clolab에서 실습을 진행. 그에 맞게 코드 수정.
mnist dataset을 가져오는 방법은 2가지.
1. keras
2. 책에서 제공하는 mnist를 colab에 업로드
1. keras 이용
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()

형상을 확인해보면 책과 다르다.
책은 (60000, 784) 로 나온다.
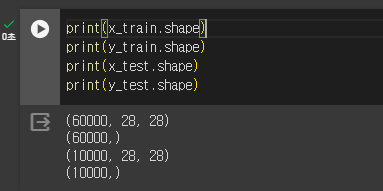

책에서 제공하는 데이터셋은 2차원(28x28)의 이미지를 flatten =True 처리했기에 1차원(784)으로 나온다.
동일한 형태(1차원)로 변경하자.
numpy reshape를 이용.
import numpy as np
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
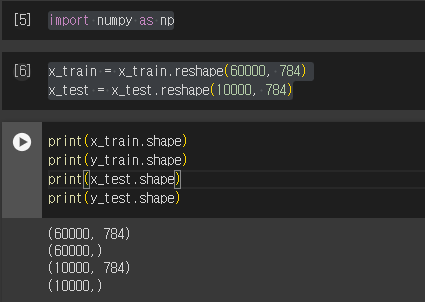
책과 동일한 1차원 형태로 변경 완료.
x는 이미지 정보이기 때문에 2차원에서 1차원으로 변경을 한것이고
y는 라벨값이기때문에 변경 할 필요가 없음.
https://numpy.org/doc/stable/reference/generated/numpy.reshape.html#numpy-reshape
numpy.reshape — NumPy v1.26 Manual
Read the elements of a using this index order, and place the elements into the reshaped array using this index order. ‘C’ means to read / write the elements using C-like index order, with the last axis index changing fastest, back to the first axis ind
numpy.org
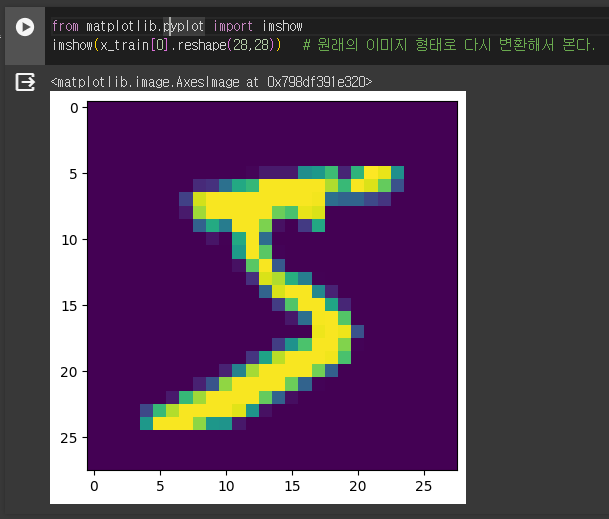
mnist 손글씨 이미지 확인.
colab 환경에서는 PIL (pillow)를 사용 할 수 없다.
matplotlib의 imshow를 사용해서 이미지를 확인한다.
from matplotlib.pyplot import imshow
imshow(x_train[0].reshape(28,28)) # 원래의 이미지 형태로 다시 변환해서 본다.

신경망의 추론 처리
가중치 매개변수 등록.
init_network에서 사용되는 sample_weight.pkl 파일을 colab에 upload 한다.
책에서 제공하는 github 저장소에서 파일( sample_weight.pkl)을 다운로드 받는다.
https://github.com/youbeebee/deeplearning_from_scratch/tree/master/ch3.%EC%8B%A0%EA%B2%BD%EB%A7%9D

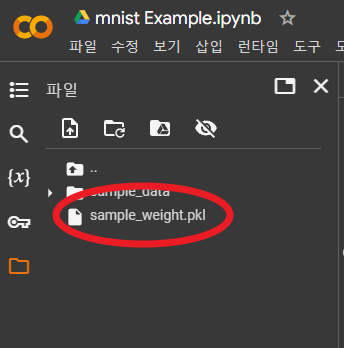
colab 좌측 메뉴에서 file아이콘(빨간 원)을 클릭한다
세션저장소에 업로드 클릭.
(현재의 세션이 끝나면 사라지므로 세션을 다시시작한다면 다시 업로드 해줘야 함.)

파일이 업로드 된것을 확인.
업로드한 파일을 load하기 위해 pickle을 install
!pip install pickle5
import pickle5 as pickle

함수 정의.
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def softmax(a) :
c = np.max(a)
exp_a = np.exp(a - c) # 입력신호 a의 지수함수
sum_exp_a = np.sum(exp_a) # 모든입력신호의 지수함수
y = exp_a / sum_exp_a
return y
def init_network():
with open('/content/sample_weight.pkl', 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
# get_data 함수는생략. 위에서 구현한것으로 대체.
get_data() 함수의 재정의
현재 x_test, y_test 는 normalize(정규화) 가 되어있지 않다.
그 말인즉슨 각 이미지의 픽셀값을 그대로 가지고 있다는 것이다. 픽셀은 0~255 의 값으로 정의되기에
이미지 정보의 값을 확인하면 0~255사이의 값이 지정되어있다.

이걸 정규화 해준다.
그래야 정확도가 올라간다.
x_train = x_train / 255
x_test = x_test / 255
그러면 값이 0.0~ 1.0의 값으로 변환된다.

정확도 구하기.
x = x_test # get_data() 함수 대체. 정규화(normalize) 완료.
network = init_network()
accuracy_cnt = 0;
for i in range(len(x)) :
y = predict(network, x[i])
p = np.argmax(y) # 확률이 가장 높은 원소의 인덱스를 얻는다.
if p == t[i]:
accuracy_cnt += 1
print('accuracy : ' + str(float(accuracy_cnt) / len(x)))

정확도 : 0.9352
'Programming' 카테고리의 다른 글
| 신경망의 학습 - 손실함수 (0) | 2024.01.01 |
|---|---|
| 신경망 - 활성화함수 : 계단, 시그모이드, ReLU 함수. (1) | 2023.12.31 |
- Total
- Today
- Yesterday
- 밑바닥부터 시작하는 딥러닝
- 다이소 방울토마토
- 젤카야노 25
- 바질
- 다이소 바질
- forerunner265
- 치커리
- 비트
- 비트 키우기
- 가민 포러너
- 포러너 245 뮤직
- 리액트 인피니티 런
- 진미영
- 다이소 씨앗
- 가민
- 나이키 리액트 인피니티 런 플라이니트
- 베란다에서 비트 키우기
- 바질 키우기
- 적상추
- 나이키
- 방울토마토
- 베란다에서 식물키우기
- forerunner 245 music
- 바질 재배
- 방울토마토 재배
- 포러너245
- garmin
- 포러너 245
- 베란다에서 식물 키우기
- 방울토마토 키우기
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |